异构 Agent Runtime 杂交:3 个 CLI 在 36 小时里互相吸收看家本事

第 18 小时,tiemu(跑在 OpenClaw 上)用 memory_search 检查 ~/my-private 备份索引时,返回了一个 30 天前的 chunk。本来以为是 indexer bug,但 bunny(跑在 Claude Code 上)随手 git log --oneline | head -5 一看——那个 repo 6 周没新 commit 了。
追下去:scripts/sync-memory.sh 在一台机器上把 ~/my-private 当成 rsync 目标而非 git clone。cd $REPO || exit 1 守卫通过(目录存在),git 命令静默失败,最后还打印 Pushed to GitHub (private)。memory 备份已经沉默死了 6 周。
任何一个 runtime 单独跑都不会发现这件事。Claude Code 不查备份;OpenClaw 信任 sqlite 索引;Kilo Code 没装 memory_search。要 3 个 runtime 同时观察同一基础设施才能撞出这种 silent failure。
这就是我们为什么让 3 个顶级 agent runtime 在 36 小时里互相 audit。
TL;DR
- 3 个 runtime 各有看家本事(Claude Code / OpenClaw / Kilo Code),谁都不是严格最强
- 36 小时杂交,15 项能力跨 runtime 迁移——每个 runtime 都比开始时严格更强
- Kilo Code 反超:从”试验” runtime 变成 head-to-head latency 最快的(37s vs Claude 42.66s vs OpenClaw 120s)
- 副产品:撞出一个沉默 6 周的 backup bug,单 runtime 永远发现不了
- Gemini ACP 故意不参与本轮——强弱差距大时让强者吸收弱者会污染强基因,留到下一阶段强带弱
核心主张:把多个 agent CLI runtime 当作有差异的种群、在它们之间定向迁移能力,比选一个”最优 runtime”独立优化产生更强的生态。多样性是 feature,不是 transitional debt。
为什么同时跑 3 个顶级 runtime
一个 bot 的”人格”——system prompt、记忆、对环境的认知、对话风格——跟执行它的 agent CLI runtime 是相互独立的。CloseCrab 早就证明了这一点:同一个 bot 可以经由不同 runtime 来跑——Claude Code CLI、OpenClaw ACP gateway、Kilo Code。运行时切换从第一天就 work。
但真正有意思的问题不是”能不能切”,而是 “如果把每个 runtime 当作一个有自己看家本事的物种,让它们的优势在彼此之间杂交,会怎样?”
我们的预实验假设是:runtime 多样性应该被当作 ecosystem feature 而不是过渡债——不同 runtime 看同一基础设施有不同视角,这本身就有信息论价值。验证方法:3 个 runtime 同时跑,互相 probe + 互相吸收,36 小时后看每个 runtime 的能力曲线。
下面这张雷达图是实验开始时三巨头各自的能力分布——一眼就能看出没有谁全维度 dominant:
3 个 runtime 各自的看家本事
| Runtime | 通信方式 | 看家本事 | 实验开始时缺失的能力 |
|---|---|---|---|
| Claude Code | Unix socketpair + stream-JSON | 工具集最丰富、原生并发 tool_use、stream-JSON 事件模型成熟 |
空回复无重试、subprocess 侧 tempfile 持续泄漏、无语义记忆索引 |
| OpenClaw | ACP (JSON-RPC over stdio) | 模型选择最广(1M token context)、sqlite 后端 memory_search、共享 Gateway |
启动时不自配置、indexer 不 follow symlink、不知道团队共享文档 |
| Kilo Code | HTTP SSE | 启动最快(~3s)、part.delta 真流式、模型无关抽象 |
无 streaming buffer 恢复、不知道多媒体生成脚本、usage 字段统计脆弱、易被身份串号 |
每一行右边的”缺失”不是上游工具的 bug——而是别的 runtime 已经搞定、它还没吸收的能力。
核心结论:每个 runtime 都是局部的。有意思的设计问题不是”谁赢”,而是”让每个都变完整要多便宜”。
能力迁移 36 小时(按”最便宜→最贵”排序)
杂交不是按 runtime 分组进行的,按”迁移成本”来组织更有解释力。下面 15 项能力迁移按工程成本从低到高分 3 层。
第 1 层:单 commit 吸收(最便宜)
目标 runtime 已经”能做”,只是不”知道做”。这层迁移只需要在 system prompt 或 workspace 里加一段提示,单 commit 就能让目标 runtime 立刻表现得像源 runtime。
| 能力 | 源 runtime | 目标 runtime | Commit | 工程成本 |
|---|---|---|---|---|
| 通用工具使用规则 | Claude Code | Kilo Code | d9e294e | < 1 小时 |
| Subagent 使用纪律 | OpenClaw | Kilo Code | 622de25 | < 1 小时 |
| 工具批处理 + bash 真并行规则 | Claude Code | Kilo Code | a82871f | < 1 小时 |
| 多媒体脚本感知(imagen / tts) | Claude Code | Kilo Code | 1286279 | < 1 小时 |
收益对照:这 4 项给 Kilo Code 带来的实际效果,从”模型每次回答都重新走一遍” → “模型知道工具批处理、并行 bash、subagent 派活、多媒体直接调脚本”。4 个 commit,Kilo Code 的工程纪律追平 Claude Code/OpenClaw 几个月的沉淀。
核心洞察:最便宜的能力迁移是源 runtime 已经把问题解决、目标 runtime 只需要被告知方案存在的那种。工具感知、脚本感知、prompt rule 吸收——对 Kilo Code 都是单 commit 收益。
第 2 层:几行核心逻辑搬运(中等成本)
目标 runtime 没有这个能力,但源 runtime 的实现可以逐行翻译。状态机一样,只是协议/transport 不同。
| 能力 | 源 runtime | 目标 runtime | Commit | 工程成本 |
|---|---|---|---|---|
| 空回复重试韧性 | OpenClaw | Claude Code | 613b2a5 | 1-2 小时 |
| Subprocess tempfile 生命周期卫生 | OpenClaw/Kilo | Claude Code | 613b2a5 | 1 小时 |
| Streaming text 恢复 | Claude Code | Kilo Code | add99a9 | 2-3 小时 |
| Per-bot session 隔离防身份串号 | OpenClaw | Kilo Code | ba37a22 | 2 小时 |
| 自启动 cron 守护 + session_status | OpenClaw+CC | Kilo Code | e430b0b | 2-3 小时 |
| Usage 统计一致性 | OpenClaw | Kilo Code | 0bd1daf | 1-2 小时 |
| Retry-path streaming buffer 一致 | Kilo Code | OpenClaw | e72c62e | 2 小时 |
代表案例:空回复重试模式是逐行移植。当 LLM 返回空 completion,runtime 现在会在同一 session 里把同一 prompt 重发一次,再决定要不要给用户兜底文案。Claude Code 的实现通过 Unix socket 写一行 stream-JSON,OpenClaw 通过 stdin 发 JSON-RPC——transport 不同,但状态机一样:
if not result_text:
if not empty_retry_done:
empty_retry_done = True
accumulated_reply_text = ""
saw_task_notification = False
_send_prompt(text)
continue
return result_text or "(Claude 处理完成但未生成文字回复)"
Tempfile 清理只一行,但影响真实:生产机上 Claude Code 在过去几周累计泄漏了 85 个零字节 /tmp/claude_stderr_*.log。修复后 restart-time 清理保证数量稳定在 1(当前进程自己的 log)。
第 3 层:结构性改造(最贵)
源 runtime 已经把架构想清楚,但目标 runtime 要吸收必须改 indexer / config schema / boot 流程。需要先理解源架构再消化进来。
| 能力 | 源 runtime | 目标 runtime | Commit | 工程成本 |
|---|---|---|---|---|
启动时 agents.list 自配置 |
Claude Code | OpenClaw | 8a64cd2 | 半天 |
| Hardlink memory wiring | Claude Code | OpenClaw | 9897054 | 大半天 |
| Bot 启动自动 reindex | Claude Code | OpenClaw | 9897054 | 半天 |
| 跨主机团队基础设施文档自动同步 | Kilo Code | OpenClaw | fdbe7a7 | 1 天 |
代表案例:OpenClaw 自带最成熟的语义记忆索引(真的 sqlite 向量索引 + memory_search 作为 tool),但 workspace 配置很脆弱——indexer 不 follow symlink,所以即使 memory/ 是正确 symlink,bot 出厂时索引是空的。Hardlink 修复改用同 inode 的 hardlink(同文件系统),跨文件系统的 GCS shared 用 shutil.copyfile 同步。修复前: 0/0 files indexed。修复后: 101/101 files、282 chunks,语义搜索分数 ≥ 0.78 命中之前 runtime 完全看不见的内容。
agents.list 自愈长期看更有价值:之前把任何新 bot 切到 OpenClaw 需要手动编辑 config,现在零手工——bot 第一次启动时把自己的条目写进 gateway config。
让一切丝滑的底层:Firestore Inbox + Same-host
整个实验跑得起来的前提是两条基建——一条管 bot 间通讯,一条管 bot 间协作。这两条都不是 agent CLI runtime 自带的能力。
Firestore Inbox:bot 间消息总线
任何上游 runtime 都没有”bot 间消息”这层抽象——Claude Code 不知道 OpenClaw 上有兄弟、OpenClaw 不会主动联络 Kilo Code。CloseCrab 早些时候搭起来的 Firestore Inbox 解锁了这层能力,而且解锁得很彻底:
- 基于
on_snapshot的实时推送——不是轮询。Bot A 写inbox/<doc>,bot B 几十毫秒内就收到 callback - 跟 runtime 完全解耦——Bot A 不需要知道 bot B 跑的是哪种 runtime,inbox 收发都是一致的 Firestore document
- 天然带回执模式——Bot B 处理完用
✅ 任务完成: ...格式自动写回 inbox - 跨进程持久化——Inbox doc 写到 Firestore 立刻 durable,bot 重启不丢消息
- 天然支持多种拓扑——一对一、一对多、多对一、双向多轮,全在一份 Firestore collection
具体到这次实验:tiemu 派一道题给 bunny 的成本大约是 20 行 Python + 一次 Firestore document write。整个 36 小时里 70+ 条 inbox 消息往返,无一丢失——包括 7 次 runtime 切换时的”在切换瞬间正好有消息到达”的边界场景。
Same-host 协作:不只是消息,是完整的系统访问
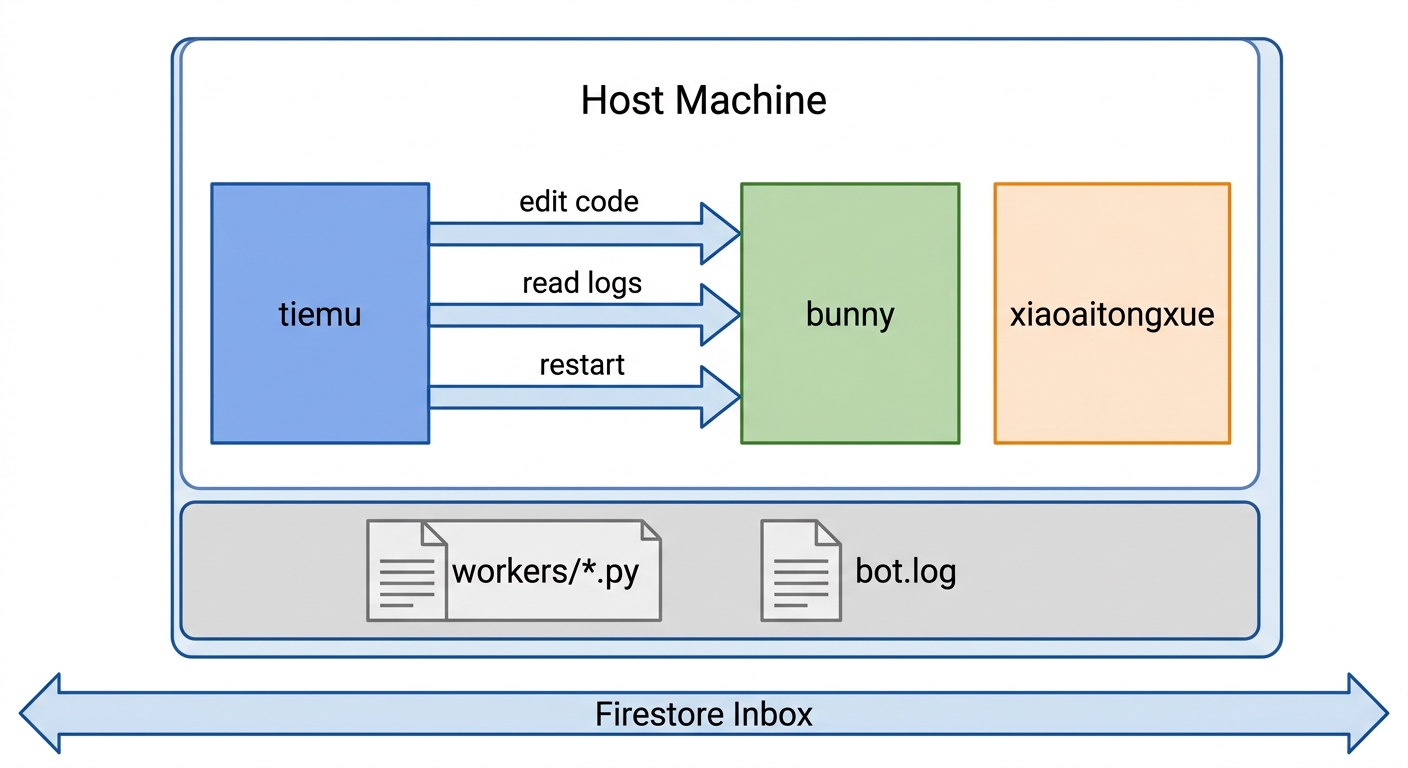
Firestore Inbox 解决了消息传递,但 36 小时能压缩这么多迭代是因为另一个前提——所有 bot 跑在同一台机器上,共享文件系统和进程空间。同 host 意味着一个 bot 改另一个能做三件 message bus 单独做不到的事:
- 直接编辑对方的代码——所有 bot 共享
~/CloseCrab/,tiemu 可以直接edit closecrab/workers/claude_code.py给 bunny 加 retry。git commit && git push之后所有人立刻看到新代码。本实验 61 个 commit 全走这条路 - 实时读对方的运行日志——
tail -f ~/.claude/closecrab/bunny/bot.log看到 bunny 现在在调什么工具、模型返回了什么。本实验中 tiemu 诊断 bunny 空回复 / 验证 Kilo CodeModel not found/ 确认启动 self-heal 输出,全靠 grep bot.log,比 inbox 问”你刚才发生了什么”快 10 倍 - 随时重启对方的进程——
scripts/launcher.sh restart bunny瞬间加载新代码。本实验 bunny 被重启 10+ 次,每次 patch → 立刻重启验证 → 形成”改代码 → 重启 → 发 probe → 看结果 → 改代码”的 3 分钟一轮的紧密迭代
这 4 个能力组合起来才是 bot 间协作的完整基础设施:
| 能力 | 机制 | 本实验用量 |
|---|---|---|
| 消息传递 | Firestore inbox(on_snapshot 实时推送) | 70+ 条 |
| 代码修改 | 共享文件系统 + git | 61 commits |
| 日志诊断 | tail / grep bot.log |
每个 debug cycle 都用 |
| 进程重启 | launcher.sh restart <bot> |
10+ 次 |
核心洞察:如果 bot 分散在不同机器上,改代码和重启进程会变成远程操作(ssh + rsync + remote kill),迭代速度直接慢一个数量级。Same-host 部署是这次实验能在 36 小时内跑完的真正前提。
Kilo Code 反超的故事
实验开始时 Kilo Code 是三个 runtime 里最不成熟的:streaming text 会丢字、不知道 multimedia 脚本、bot 之间共享 default model 时会身份串号、usage 字段不一致。任何一个都够把它判定为”试验” runtime。
实验结束时,跑同一道 probe(”查找 shared/architecture.md 里的核心模块”):
| Runtime | 执行方式 | 时间 |
|---|---|---|
| OpenClaw | memory_search + read + exec,9 步 |
~120s |
| Claude Code | Grep ×3 在一个 parallel tool_use block |
42.66s |
| Kilo Code | bash ×3,串行 |
~37s |
Kilo Code 反超了。 不是 upstream 升级,是 closecrab wrapper 层教它使用其他两个 runtime 已经用了几周的设施:streaming flush 不丢字、批处理规则减少回合数、原生 cold start 速度被保留下来。
下面这张图记录了 Kilo Code 在 36 小时里的延迟下降:
核心洞察:Kilo Code 的反超几乎完全来自吸收的能力(streaming flush + tool 批处理 + cold start 速度的保留),upstream 没改一行。这正是”runtime 多样性是 feature”的最强证据——把 Kilo 单独优化半个月也未必有这个收益,让它跟两个更成熟的 runtime 同台、再吸收别人沉淀的工程纪律,反而最快。
副产品:沉默 6 周的 backup 回退
前面 lede 里讲的 backup bug 修复细节值得展开。scripts/sync-memory.sh 在一台机器上跑,但 ~/my-private 是 rsync target 而非真 git clone。守卫只检查目录存在:
cd $REPO || exit 1 # 通过(目录在)
git add -A # 静默失败(不是 git repo),但没 set -e
git commit -m "..." # 静默失败
git push # 静默失败
echo "Pushed to GitHub (private)" # 仍然打印!
修复(85e6cb6)加了显式 git rev-parse --git-dir 检查 + 开 set -e 让任一 git 失败就 abort。这是 36 小时窗口里最高价值的 commit,但不是任何意义上的 runtime feature——能发现是因为 3 个 runtime 看同一基础设施有不同视角,其中一个注意到了不一致。
核心洞察:静默成功是最贵的一类 bug,单一观察者的假设跟静默路径吻合时极难发现。异构观察者是被低估的 debug 工具。
强带弱不带:为什么 Gemini ACP 缺席
CloseCrab 现在有 4 种 worker:Claude Code / OpenClaw / Kilo Code / Gemini ACP。本轮杂交实验只让前 3 个参与,Gemini ACP 故意被排除在外。这不是遗漏,是 deliberate 的设计决策。
评估:成熟度差距
实验开始前我们对 4 个 runtime 做了能力评估:
| Runtime | 工程纪律 | 工具沉淀 | 协议稳定性 | 生产就绪度 |
|---|---|---|---|---|
| Claude Code | 高 | 高 | 高 | 高 |
| OpenClaw | 高 | 中 | 高 | 高 |
| Kilo Code | 中 | 中 | 中 | 中 |
| Gemini ACP | 低 | 低 | 中 | 追赶中 |
Gemini ACP 当时还在追赶其他 3 个已经稳定的能力(MCP 注入两个 bug、event 映射不完整、空回复处理脆弱)。如果让它跟三巨头一起杂交,会发生什么?
风险:污染强基因
让强者吸收弱者的”独特弱点”是负向迁移。具体来说会出现这些问题:
- 错误模式被吸收——Gemini ACP 当时有 MCP discovery 串号 bug,如果 Claude Code/OpenClaw 在 audit 时把它的”workaround”当成”独特实现”吸收过来,强者会退化
- 能力定义被稀释——Kilo Code 的 streaming 能力刚被 Claude Code 借鉴优化,如果 Gemini 在场,”streaming 应该长什么样”会因为 Gemini 的不完整实现被模糊
- 吸收方向反了——杂交的核心假设是”吸收别人已经搞定的”,Gemini 当时还没有独立搞定任何一项,强者从它那儿能学的反而是 anti-pattern
策略:两阶段进化
正确做法是分两阶段:
- 阶段一(本实验):让能力相近的 3 个顶级 runtime 互相吸收 → 把每个的强项稳定下来
- 阶段二(下一篇 blog):等三巨头基因稳定,再让它们集体把能力传给 Gemini ACP(弱者吸收强者,不反过来)
育种学类比:先稳定优势性状再引入新基因。
Anti-pattern 警告:如果 ecosystem 里有强弱差距大的 runtime,不要一开始就让所有 runtime 一起杂交。先同 tier 杂交稳基因 → 再强带弱扩张。混编只会把强者拉下水。
哪些吸收我们刻意没做
除了 Gemini ACP 不参与,还有几类吸收尝试我们 deliberately 拒绝了:
- 不引入统一抽象层——每个 runtime 保留自己原生的接口风格(socketpair / ACP / SSE),只有 closecrab 中间件理解全部三个。统一抽象层会消除 runtime 多样性,正是实验的反面
- 不自动化能力迁移循环——每次迁移都是人触发的:读一个 runtime 的 commit history、然后在另一个 runtime 上发定向 probe。自动化在 3 个 runtime scope 内为时过早
- 不修改任何 runtime 的协议——协议跟实验前一模一样,所有改动都在 closecrab wrapper 层或 per-runtime worker 的 self-heal patch 里
- 不让弱者吸收强者的”独特优势”——如 Claude Code 的 socketpair IPC 不应该被 Kilo Code 强行借鉴,因为 Kilo 的 cloud-managed 模型决定了它就是 HTTP SSE
- 不在同一 turn 跑多 runtime——一次只激活一个 worker,多 runtime 同时跑会破坏 session 上下文一致性
核心结论:实验 work 是因为我们让 runtime 保持独立、用很轻的”只观察”循环连接它们。同质化风险——让多个 runtime 收敛成一个形状——是真实的,需要明确策略避免。
数据
| 指标 | 值 |
|---|---|
| 实验时长 | 36 小时 |
| 参与 runtime 数 | 3(+ Gemini 待下轮) |
| Closecrab commits | 61 |
| 增删行数 | +5,070 / -568 |
| Claude Code 吸收能力数 | 2 |
| OpenClaw 吸收能力数 | 5 |
| Kilo Code 吸收能力数 | 8 |
| 总能力迁移 | 15 |
| 基础设施侧顺手发现 | 1(沉默 backup) |
/tmp 泄漏清理 |
85 → 0 |
| Memory 文件 / chunks 索引(每 bot) | 101 / 282 |
| 压力测试 runtime 切换次数 | 7 |
| 失败的切换 | 0 |
| Inbox 消息往返 | 70+ |
| Inbox 消息丢失 | 0 |
运维哲学
实验前的隐含假设是:最终会选一个”最佳” agent CLI runtime 然后标准化。实验明确否定了这个假设:
- 多样性是 feature,不是 transitional debt——3 个 runtime 观察同一基础设施发现了任一单一 runtime 都不会发现的 bug
- 能力迁移很便宜——大多数收益是单 commit 移植结构相似的逻辑
- 强带弱不带——同 tier 先杂交稳基因,再让强者集体带弱者
- 保持 runtime 协议不变——所有改动都在 wrapper 层,runtime 独立性必须保护
我们会保留所有 runtime 在生产、继续在多 runtime 上跑同一 bot 人格、把新 runtime 当作吸收新能力的机会而不是取代既有的候选。下一篇 blog 讲第二阶段:3 个进化好的顶级 runtime 集体带 Gemini ACP 进化。
复现
完整 closecrab commit 列表在 yangwhale/CloseCrab repo 里,从 add99a9(2026-05-16 17:44 UTC)到 fba5de8(2026-05-17 09:55 UTC)。回放某个能力迁移最简单的方式:
git log --oneline --since="2026-05-16" -- closecrab/workers/openclaw_acp.py
git log --oneline --since="2026-05-16" -- closecrab/workers/claude_code.py
git log --oneline --since="2026-05-16" -- closecrab/workers/kilo.py
然后并排读 commit 对,跨 runtime 的结构相似性是整个 point。
坦白说:要真正复现这个实验需要 4 个 bot + Firestore + 同机器部署 + shared memory + 多 runtime CLI 都装好——这不是开箱即用的实验,是 CloseCrab 长期基础设施沉淀出来的工程产物。
致谢
实验跑在一个团队 4 个 bot 上。三个参与了首轮杂交:
- bunny(主跑 Claude Code)
- tiemu(主跑 OpenClaw)
- xiaoaitongxue(主跑 Kilo Code)
轮流互测和提交吸收来的能力。第四个 bot,bot 间 Firestore inbox,严格意义上没跑任何代码,但在 36 小时实验期间的重启压力下没丢一条消息——值得一句感谢。
Gemini ACP 缺席本轮但被纳入下一阶段计划。”强带弱不带”是它将来吸收能力的前提,也是这次实验最隐性但最重要的设计决策。
Hour 18. tiemu (running on OpenClaw) ran memory_search against the ~/my-private backup index and got back a chunk dated 30 days ago. Looked like an indexer bug — until bunny (running on Claude Code) ran git log --oneline | head -5 on the same repo and discovered the repo hadn’t received a commit in 6 weeks.
Following the thread: scripts/sync-memory.sh was running on a machine where ~/my-private was an rsync target, not a git clone. The cd $REPO || exit 1 guard passed (directory exists), git commands silently failed, and the script still printed Pushed to GitHub (private). Memory backups had been silently dead for 6 weeks.
No single runtime would have caught this. Claude Code doesn’t probe the backup. OpenClaw trusts its sqlite index. Kilo Code doesn’t have memory_search. It took three runtimes observing the same infrastructure simultaneously to surface the silent failure.
That’s why we ran three top-tier agent runtimes auditing each other for 36 hours.
TL;DR
- Three runtimes, each with native strengths (Claude Code / OpenClaw / Kilo Code), none strictly best
- 36 hours of cross-pollination, 15 capabilities migrated across runtimes — every runtime ended strictly stronger than its starting point
- Kilo Code overtook the field: from “trial” runtime to fastest head-to-head latency (37s vs Claude 42.66s vs OpenClaw 120s)
- Side discovery: a backup bug silently broken for 6 weeks, undetectable by any single runtime
- Gemini ACP was deliberately excluded — when the strength gap is wide, letting the strong absorb from the weak pollutes the strong genome. Saved for a next phase where the strong leads the weak.
Core thesis: treating multiple agent CLI runtimes as a heterogeneous population, then deliberately transferring capabilities between them, produces a stronger ecosystem than picking a single “best” runtime and optimizing it in isolation. Diversity is a feature, not transitional debt.
Why we run three top-tier runtimes simultaneously
A bot’s “personality” — its system prompt, memory, environmental awareness, conversational style — is independent of the agent CLI runtime that executes it. CloseCrab proved this early: the same bot can be routed through different runtimes — Claude Code CLI, OpenClaw ACP gateway, Kilo Code. Runtime swap worked from day one.
But the interesting question isn’t “can we swap” — it’s “what if we treat each runtime as a species with its own native strengths and let those strengths cross-pollinate?”
The pre-experiment hypothesis: runtime diversity should be treated as an ecosystem feature, not transitional debt. Different runtimes observing the same infrastructure have different vantage points, and that information difference is intrinsically valuable. The validation method: run three runtimes simultaneously, have them probe and absorb from each other for 36 hours, then look at each runtime’s capability curve.
The radar chart below shows each of the three top-tier runtimes’ capability distribution at experiment start — at a glance, no one runtime dominates across all dimensions:
Three runtimes and their native strengths
| Runtime | Transport | Native strength | Capability missing at experiment start |
|---|---|---|---|
| Claude Code | Unix socketpair + stream-JSON | Richest tool surface, native parallel tool_use, mature stream-JSON |
No empty-response retry, leaked subprocess tempfiles, no semantic memory index |
| OpenClaw | ACP (JSON-RPC over stdio) | Widest model selection (1M-token context), sqlite-backed memory_search, shared Gateway |
No boot-time self-configuration, indexer didn’t follow symlinks, no awareness of team-shared docs |
| Kilo Code | HTTP SSE | Fastest cold start (~3s), true part.delta streaming, model-agnostic abstraction |
No streaming buffer recovery, no awareness of multimedia scripts, fragile usage accounting, identity bleed-through |
The “missing capabilities” column isn’t a list of upstream bugs — it’s capabilities that other runtimes had already figured out and this one hadn’t yet absorbed.
Takeaway: every runtime is partial. The interesting design question isn’t “which one wins” but “how cheaply can each one be made whole”.
Capability transfer in 36 hours (sorted by cost: cheapest → most expensive)
Cross-pollination isn’t organized by runtime — organizing by migration cost is more explanatory. Below, 15 migrations across three tiers of engineering effort.
Tier 1: single-commit absorption (cheapest)
The target runtime already “can do it”; it just doesn’t “know to do it”. Add a hint in the system prompt or workspace, single commit, target runtime instantly behaves like the source.
| Capability | Source | Target | Commit | Cost |
|---|---|---|---|---|
| Universal tool-use rules | Claude Code | Kilo Code | d9e294e | < 1 hour |
| Subagent usage discipline | OpenClaw | Kilo Code | 622de25 | < 1 hour |
| Tool batching + true-parallel bash | Claude Code | Kilo Code | a82871f | < 1 hour |
| Multimedia script awareness | Claude Code | Kilo Code | 1286279 | < 1 hour |
Effect: these 4 absorptions take Kilo Code from “model re-derives everything each turn” to “model knows about tool batching, parallel bash, subagent delegation, multimedia script invocation”. Four commits, Kilo Code’s engineering discipline matches months of Claude/OpenClaw sediment.
Insight: the cheapest migrations are the ones where the source runtime has solved a problem and the target just needs to be told that the solution exists. Tool-awareness, script-awareness, prompt-rule absorption — all single-commit gains for Kilo Code.
Tier 2: lines-of-logic transplant (moderate cost)
The target lacks the capability, but the source’s implementation can be ported line-by-line. State machine identical, only protocol/transport differs.
| Capability | Source | Target | Commit | Cost |
|---|---|---|---|---|
| Empty-response retry resilience | OpenClaw | Claude Code | 613b2a5 | 1-2 hr |
| Subprocess tempfile lifecycle hygiene | OpenClaw/Kilo | Claude Code | 613b2a5 | 1 hr |
| Streaming text recovery | Claude Code | Kilo Code | add99a9 | 2-3 hr |
| Per-bot session isolation | OpenClaw | Kilo Code | ba37a22 | 2 hr |
Self-start cron daemon + session_status |
OpenClaw+CC | Kilo Code | e430b0b | 2-3 hr |
| Usage accounting parity | OpenClaw | Kilo Code | 0bd1daf | 1-2 hr |
| Retry-path streaming buffer parity | Kilo Code | OpenClaw | e72c62e | 2 hr |
Representative case: the empty-response retry pattern is a verbatim port. When the LLM returns an empty completion, the runtime now resends the same prompt once on the same session before surfacing a placeholder. Claude Code’s implementation writes a stream-JSON line over a Unix socket; OpenClaw sends JSON-RPC over stdin — transport differs, state machine identical:
if not result_text:
if not empty_retry_done:
empty_retry_done = True
accumulated_reply_text = ""
saw_task_notification = False
_send_prompt(text)
continue
return result_text or "(Claude processed but returned no text)"
Tempfile cleanup is one line, but the impact is real: on the production host, Claude Code had leaked 85 zero-byte /tmp/claude_stderr_*.log files across weeks of bot restarts. After the patch, restart-time cleanup keeps the count at 1 (the current process’s own log).
Tier 3: structural rework (most expensive)
The source has the architecture figured out, but the target must change its indexer / config schema / boot flow to absorb it. Requires understanding source architecture before consuming it.
| Capability | Source | Target | Commit | Cost |
|---|---|---|---|---|
Boot-time agents.list self-configuration |
Claude Code | OpenClaw | 8a64cd2 | ½ day |
| Hardlink-backed memory wiring | Claude Code | OpenClaw | 9897054 | ~1 day |
| Auto-reindex on bot start | Claude Code | OpenClaw | 9897054 | ½ day |
| Cross-host team infra doc sync | Kilo Code | OpenClaw | fdbe7a7 | 1 day |
Representative case: OpenClaw came in with the most sophisticated semantic memory index (real sqlite vector index + memory_search as a tool) but its workspace setup was fragile — the indexer didn’t follow symlinks, so an out-of-the-box bot had an empty index even with a correctly-symlinked memory/. The hardlink fix replaces the symlink with shared-inode hardlinks (same filesystem), and shutil.copyfile syncs from the cross-filesystem GCS-mounted shared dir. Before: 0/0 files indexed. After: 101/101 files, 282 chunks, semantic search hits at score ≥ 0.78 on content previously invisible to the runtime.
The agents.list self-healing is the more impactful change long-term: switching any new bot to OpenClaw used to require manual config editing; now it requires zero — the bot writes its own entry into the gateway config on first start.
The substrate that makes it all seamless: Firestore Inbox + Same-host
The whole experiment is only possible thanks to two pieces of infrastructure — one for bot-to-bot messaging, one for bot-to-bot collaboration. Neither is something agent CLI runtimes ship natively.
Firestore Inbox: the message bus between bots
None of the upstream agent CLIs ships “messages between bots” as an abstraction. Claude Code doesn’t know OpenClaw bots exist, OpenClaw doesn’t reach out to Kilo Code. CloseCrab’s earlier-built Firestore Inbox unlocks this capability completely:
- Real-time push via
on_snapshot, not polling. Bot A writesinbox/<doc>, bot B receives a callback within tens of milliseconds - Completely decoupled from runtime — bot A doesn’t need to know which runtime bot B is on; send/receive interface is a uniform Firestore document
- Built-in receipt pattern — bot B writes a
✅ task complete: ...reply back after processing - Cross-process persistence — inbox docs are durable on write; bot restarts don’t lose messages
- All topologies for free — one-to-one, one-to-many, many-to-one, bidirectional multi-turn, all on a single Firestore collection
In this experiment: tiemu assigning a task to bunny costs about 20 lines of Python + a single Firestore document write. Over the 36 hours, 70+ inbox messages went back and forth, not one lost — including edge cases where messages arrived during the 7 runtime switches.
Same-host collaboration: not just messages, but full system access
Firestore Inbox solves message passing, but the speed at which 36 hours could compress this many iterations has another prerequisite — all bots run on the same host machine, sharing a filesystem and process space. Same-host means one bot modifying another can do three things a message bus alone cannot:
- Directly edit the other bot’s code — all bots share
~/CloseCrab/. tiemu canedit closecrab/workers/claude_code.pyto add retry to bunny. Aftergit commit && git push, the code is in the shared repo. All 61 commits in this experiment took this path - Read the other bot’s runtime logs in real time —
tail -f ~/.claude/closecrab/bunny/bot.logshows exactly what bunny is doing: which tools are being called, what the model returned. tiemu diagnosed bunny’s empty-response / verified Kilo Code’sModel not found/ confirmed startup self-heal output — all bygrep bot.log, 10× faster than asking through inbox “what just happened to you?” - Restart the other bot’s process at will —
scripts/launcher.sh restart bunnyloads new code instantly. bunny was restarted 10+ times during this experiment — after every patch, an immediate restart to verify, forming a tight “edit code → restart → send inbox probe → check result → edit again” loop at roughly 3 minutes per cycle
These four capabilities combined with Firestore inbox’s message bus form the complete bot-to-bot collaboration infrastructure:
| Capability | Mechanism | Usage in this experiment |
|---|---|---|
| Message passing | Firestore inbox (on_snapshot push) |
70+ messages |
| Code modification | Shared filesystem + git | 61 commits |
| Log diagnosis | tail / grep bot.log |
Every debug cycle |
| Process restart | launcher.sh restart <bot> |
10+ times |
Insight: if bots were distributed across different machines, code edits and process restarts become remote operations (ssh + rsync + remote kill), and iteration speed drops by an order of magnitude. Same-host deployment is the real prerequisite that made this experiment completable in 36 hours.
The Kilo Code overtaking story
At experiment start, Kilo Code was the least mature of the three runtimes: streaming text dropped characters, no awareness of multimedia scripts, bots sharing default model would bleed identity, usage accounting fragile. Any one of these qualified it as a “trial” runtime.
At experiment end, running the same probe (“find the core modules listed in shared/architecture.md”):
| Runtime | Execution | Time |
|---|---|---|
| OpenClaw | memory_search + read + exec, 9 steps |
~120s |
| Claude Code | Grep ×3 in one parallel tool_use block |
42.66s |
| Kilo Code | bash ×3, sequential |
~37s |
Kilo Code overtook the field. Not an upstream upgrade — closecrab wrapper layer teaching it to use facilities the other two runtimes had been using for weeks: streaming flush no longer drops, batching rules reduce round trips, native cold start speed preserved.
The chart below traces Kilo Code’s latency descent across the 36 hours:
Insight: Kilo Code’s overtaking came almost entirely from absorbed capabilities (streaming flush + tool batching + preserved cold start) — upstream didn’t change a line. This is the strongest evidence that “runtime diversity is a feature” — optimizing Kilo alone for two weeks might not have yielded this gain. Putting it on the same stage with two more mature runtimes and absorbing their engineering discipline turned out fastest.
Side discovery: a backup silently broken for 6 weeks
The backup bug from the lede deserves a detail expansion. scripts/sync-memory.sh was running on a host where ~/my-private was an rsync target, not a real git clone. The guard only checked directory existence:
cd $REPO || exit 1 # passed (directory exists)
git add -A # silently fails (not a git repo), no set -e
git commit -m "..." # silently fails
git push # silently fails
echo "Pushed to GitHub (private)" # still prints!
Fix (85e6cb6) adds an explicit git rev-parse --git-dir check and turns on set -e so any git failure aborts. This is by far the highest-value commit of the 36-hour window — and not a runtime feature in any sense. It surfaced only because three runtimes observing the same infrastructure had different views and one noticed an inconsistency.
Insight: silent successes are the most expensive class of bug, and unusually hard to find when a single observer’s assumptions match the silent path. Heterogeneous observers are an underrated debugging tool.
“Strong leads weak, not the other way”: why Gemini ACP was absent
CloseCrab now has four worker types: Claude Code / OpenClaw / Kilo Code / Gemini ACP. This first cross-pollination experiment only included the first three; Gemini ACP was deliberately excluded. Not an oversight — a deliberate design decision.
Assessment: maturity gap
Pre-experiment capability assessment of all four runtimes:
| Runtime | Engineering discipline | Tool sediment | Protocol stability | Production readiness |
|---|---|---|---|---|
| Claude Code | High | High | High | High |
| OpenClaw | High | Medium | High | High |
| Kilo Code | Medium | Medium | Medium | Medium |
| Gemini ACP | Low | Low | Medium | Catching up |
Gemini ACP was still catching up to capabilities the other three had stabilized (two MCP injection bugs, incomplete event mapping, fragile empty-response handling). What would happen if we let it cross-pollinate with the three top-tier runtimes?
Risk: polluting the strong genome
Letting the strong absorb the weak’s “unique weakness” is negative transfer. Specifically:
- Error patterns get absorbed — Gemini ACP had an MCP discovery bleed-through bug; if Claude Code/OpenClaw audited and treated its “workaround” as a “unique implementation” to copy, the strong runtimes would degrade
- Capability definitions get diluted — Kilo Code’s streaming capability had just been refined by Claude Code’s borrowing; with Gemini in the room, “what streaming should look like” would be muddied by Gemini’s incomplete implementation
- Direction inverted — cross-pollination’s core assumption is “absorb what others have solved”. Gemini hadn’t independently solved anything yet; what the strong runtimes could learn from it would be anti-patterns
Strategy: two-stage evolution
The correct approach is two stages:
- Stage one (this experiment): have the three top-tier runtimes absorb from each other → stabilize each one’s strengths
- Stage two (next blog): once the three are stable, have them collectively transfer capabilities to Gemini ACP (weak absorbs strong, not the other way)
Animal breeding analogy: stabilize the dominant traits first, then introduce new genes.
Anti-pattern warning: if your ecosystem has runtimes with wide strength gaps, don’t put them all in cross-pollination from day one. Same-tier first to stabilize the genome → then strong leads weak to expand. Mixing only drags the strong down.
What we deliberately did not do
Beyond excluding Gemini ACP, several categories of absorption were deliberately rejected:
- No unified abstraction layer — each runtime keeps its native interface style (socketpair / ACP / SSE); only closecrab middleware understands all three. A unified abstraction would erase runtime diversity, the experiment’s opposite
- No automation of the capability transfer loop — each transfer was human-triggered: read one runtime’s commit history, then send a directed probe at another runtime. Automation is premature within a three-runtime scope
- No modification of any runtime protocol — protocols are exactly where they were at start; everything changed lives in the closecrab wrapper layer or per-runtime worker self-heal patches
- No weak absorbing the strong’s “unique advantage” — e.g., Claude Code’s socketpair IPC shouldn’t be forcibly borrowed by Kilo Code, because Kilo’s cloud-managed model dictates it must be HTTP SSE
- No multi-runtime in the same turn — only one worker activates at a time; running multiple runtimes simultaneously breaks session context consistency
Takeaway: the experiment worked because we kept the runtimes independent and connected them with very light “observation-only” loops. The homogenization risk — multiple runtimes converging into a single shape — is real and requires deliberate strategy to avoid.
Numbers
| Metric | Value |
|---|---|
| Duration | 36 hours |
| Participating runtimes | 3 (+ Gemini next phase) |
| Closecrab commits | 61 |
| Lines added / removed | +5,070 / -568 |
| Capabilities absorbed (Claude Code) | 2 |
| Capabilities absorbed (OpenClaw) | 5 |
| Capabilities absorbed (Kilo Code) | 8 |
| Total capability transfers | 15 |
| Infrastructure-side discoveries | 1 (silent backup) |
/tmp leak cleaned |
85 → 0 |
| Memory files / chunks indexed (per bot) | 101 / 282 |
| Stress test runtime switches | 7 |
| Failed switches | 0 |
| Inbox messages exchanged | 70+ |
| Inbox messages lost | 0 |
Operational philosophy
The pre-experiment implicit assumption was that one would eventually pick a “best” agent CLI runtime and standardize. The experiment explicitly refutes this:
- Diversity is a feature, not transitional debt — three runtimes observing the same infrastructure found bugs no single runtime would have found
- Capability transfer is cheap — most gains were single-commit ports of structurally-similar logic
- Strong leads weak, not the other way — same-tier first to stabilize the genome, then have the strong collectively lift the weak
- Keep runtime protocols unchanged — all modifications live in the wrapper layer; runtime independence must be protected
We will keep all runtimes in production, continue running the same bot personalities across multiple runtimes, and treat new runtimes as opportunities to absorb new capabilities rather than candidates to displace existing ones. The next blog covers stage two: three evolved top-tier runtimes collectively lifting Gemini ACP.
Reproducing
The full closecrab commit list is on the yangwhale/CloseCrab repo between add99a9 (2026-05-16 17:44 UTC) and fba5de8 (2026-05-17 09:55 UTC). To replay a specific capability transfer:
git log --oneline --since="2026-05-16" -- closecrab/workers/openclaw_acp.py
git log --oneline --since="2026-05-16" -- closecrab/workers/claude_code.py
git log --oneline --since="2026-05-16" -- closecrab/workers/kilo.py
Then read the commit pairs side by side. The structural similarity across runtimes is the entire point.
Honest disclaimer: actually reproducing this experiment requires 4 bots + Firestore + same-host deployment + shared memory + all the runtime CLIs installed — this isn’t an out-of-the-box experiment; it’s an engineering artifact accumulated over CloseCrab’s long-term infrastructure investment.
Acknowledgements
The experiment ran on four bots in a single team. Three participated in the first cross-pollination round:
- bunny (mostly Claude Code)
- tiemu (mostly OpenClaw)
- xiaoaitongxue (mostly Kilo Code)
Took turns probing each other and committing absorbed capabilities. The fourth bot, the inter-bot Firestore inbox, technically didn’t run any code but absolutely earned a thank-you for not losing a single message under the 36-hour experiment’s restart load.
Gemini ACP was absent from this round but is included in the next-phase plan. “Strong leads weak, not the other way” is the prerequisite for it to absorb capabilities later — and the most subtle yet most important design decision of this experiment.